Diamonds - Pipeline Sklearn (Encoding + Normalisation)
1. 1. Analyse du dataset
Analyse du Dataset
df = sns.load_dataset('diamonds')
df.head()
carat cut color clarity depth table price x y z 0 0.23 Ideal E SI2 61.5 55.0 326 3.95 3.98 2.43 1 0.21 Premium E SI1 59.8 61.0 326 3.89 3.84 2.31 2 0.23 Good E VS1 56.9 65.0 327 4.05 4.07 2.31 3 0.29 Premium I VS2 62.4 58.0 334 4.20 4.23 2.63 4 0.31 Good J SI2 63.3 58.0 335 4.34 4.35 2.75
2. 2. Logique de la Pipeline
Création du pipeline avec la fonction make_pipeline()
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
pipeline = make_pipeline(OrdinalEncoder(), MinMaxScaler())
Pipeline(steps=[('ordinalencoder', OrdinalEncoder()),
('minmaxscaler', MinMaxScaler())])
Création du pipeline avec la classe Pipeline
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
pipeline = Pipeline(steps=[
('MonEncodeur', OrdinalEncoder()),
('MonScaler', MinMaxScaler()),
])
Pipeline(steps=[('MonEncodeur', OrdinalEncoder()),
('MonScaler', MinMaxScaler())])
/!\ Pipeline sur toutes les colonnes du dataset
3. 3. Pipeline composée
Pipelines composées : Exécuter les transformers uniquement sur certaines colonnestrong>Pipelines composées : Exécuter les transformers uniquement sur certaines colonnes
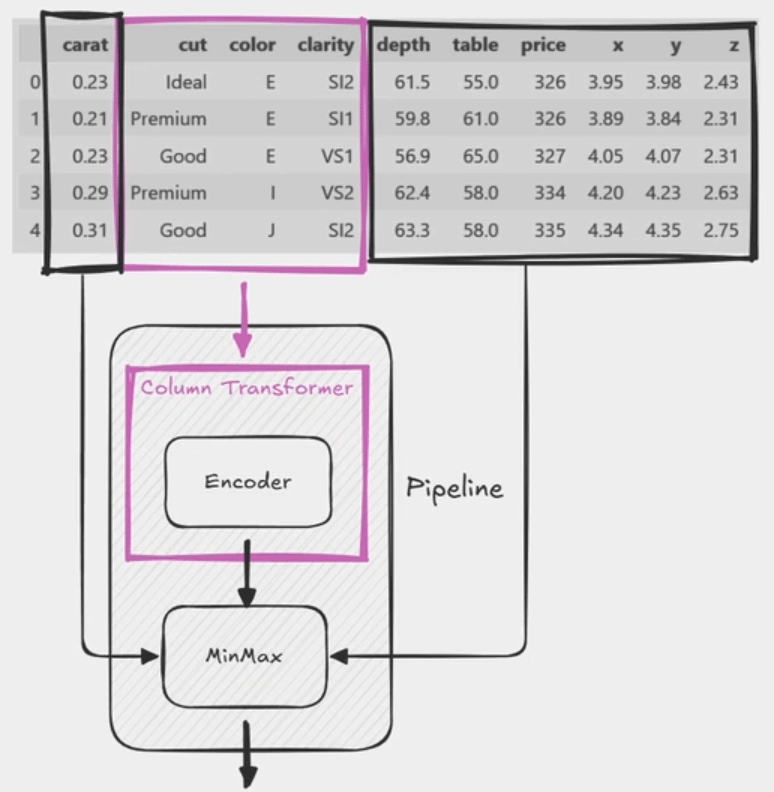
Création d'un pipeline avec un Transformer composé
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
categorial_cols = ['cut', 'color', 'clarity']
column_transformer = ColumnTransformer(transformers=[('MonEncoder', OrdinalEncoder(), categorial_cols)],
pipeline = Pipeline(steps=[
('MonEncodeur2', column_transformer),
('MonScaler', MinMaxScaler()),
])
Pipeline(steps=[('MonEncodeur2',
ColumnTransformer(remainder='passthrough',
transformers=[('MonEncoder',
OrdinalEncoder(),
['cut', 'color',
'clarity'])])),
('MonScaler', MinMaxScaler())])
Preprocessing du train set
train_set, test_set = train_test_split(df, test_size=0.2, random_state=0)
pipeline.transform(train_set)
MonEncoder__cut MonEncoder__color ... remainder__y remainder__z 26250 0.50 0.500000 ... 0.129032 0.147170 31510 0.50 0.500000 ... 0.075382 0.087107 40698 0.50 0.166667 ... 0.080985 0.092138 42634 0.75 0.666667 ... 0.090832 0.104717 47714 1.00 0.000000 ... 0.092699 0.107233 ... ... ... ... ... ... 45891 0.75 0.333333 ... 0.087267 0.098428 52416 0.25 0.000000 ... 0.093548 0.110377 42613 0.75 0.833333 ... 0.074533 0.084277 43567 0.50 0.500000 ... 0.081324 0.092138 2732 0.50 0.333333 ... 0.105093 0.119497 [43152 rows x 10 columns]
Preprocessing du test set
pipeline.fit_transform(test_set)
MonEncoder__cut MonEncoder__color ... remainder__y remainder__z 10176 0.50 0.666667 ... 0.675127 0.639191 16083 0.50 0.666667 ... 0.703553 0.676516 13420 0.75 0.833333 ... 0.690355 0.650078 20407 0.50 0.333333 ... 0.747208 0.699844 8909 1.00 0.333333 ... 0.630457 0.594090 ... ... ... ... ... ... 42208 0.25 0.666667 ... 0.517766 0.502333 3638 1.00 0.500000 ... 0.637563 0.586314 5508 1.00 0.333333 ... 0.659898 0.642302 19535 0.50 0.500000 ... 0.656853 0.617418 47950 0.25 0.166667 ... 0.507614 0.502333 [10788 rows x 10 columns]