Analyse de données
1. Introduction
2. Analyse technique d'un dataset
3. Analyse Univariée
4. Analyse Multivariée
5. Documentation
2. Analyse technique d'un dataset
3. Analyse Univariée
4. Analyse Multivariée
5. Documentation
1. Introduction
Une variable aléatoire = Un domaine (ensemble des résultats possibles) + Une loi de probabilité (fréquence d'apparition de chacun des résultats)
En pratique: Observer un échantillon et tenter d'en tirer des conclusions
=> Jamais sûr à 100%. Faire des hypothèses pour approximer les variables aléatoires.
Data Scientist: Estimation du domaine, estimation de la loi de probabilité et la confiance dans l'estimation.
Variable aléatoire discrète (fini ou infini dénombrable - se compte - Liste - Fonction de masse) <-> Variable continue (indénombrable - se mesure - Intervalle - Fonction de densité)
En pratique: Observer un échantillon et tenter d'en tirer des conclusions
=> Jamais sûr à 100%. Faire des hypothèses pour approximer les variables aléatoires.
Data Scientist: Estimation du domaine, estimation de la loi de probabilité et la confiance dans l'estimation.
Variable aléatoire discrète (fini ou infini dénombrable - se compte - Liste - Fonction de masse) <-> Variable continue (indénombrable - se mesure - Intervalle - Fonction de densité)
Analyse Fondamentale: Comprendre la signification des variables et le contexte
1. What (quoi) ? -> Sens des variables, unités
2. Who (qui) ? -> Qui a récolté les données ?
3. When (quand) ? -> Quand les données ont été collectées ?
4. Where (où) ? -> Les données sont-elles associées à une localisation ?
5. How (Comment) ? -> Comment les données ont été collectées ? (Garbage In, Garbage Out)
6. Why (Pourquoi) ? -> Pourquoi ces données ont été récoltées ? Pourquoi ai-je accès (gratuitement) à ces données ?
Analyse technique: Etude statistique, étude graphique, tests d'hyptothèses
1. What (quoi) ? -> Sens des variables, unités
2. Who (qui) ? -> Qui a récolté les données ?
3. When (quand) ? -> Quand les données ont été collectées ?
4. Where (où) ? -> Les données sont-elles associées à une localisation ?
5. How (Comment) ? -> Comment les données ont été collectées ? (Garbage In, Garbage Out)
6. Why (Pourquoi) ? -> Pourquoi ces données ont été récoltées ? Pourquoi ai-je accès (gratuitement) à ces données ?
Analyse technique: Etude statistique, étude graphique, tests d'hyptothèses
3. Analyse Univariée
3.1 Variable discrète
Calcul des effectifs
df['columnA'].value_counts(normalize=False, sort=True, ascending=False)
Distribution des effectifs
df['columnA'].value_counts(normalize=True, sort=True, ascending=False)
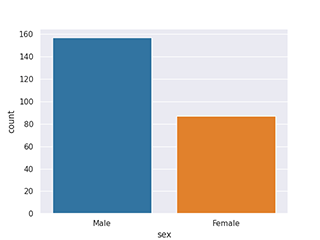
Histogramme (Bar chart) avec la librairie Pandas
df['columnA'].value_counts().plot(kind='bar')
Histogramme (Bar chart) avec la librairie Seaborn
sns.countplot(data=df, x='columnA')
3.2 Variable continue
df['column1'].describe()
df['column1'].mean()
df['column1'].median()
df['column1'].var()
df['column1'].std()
df['column1'].min()
df['column1'].max()
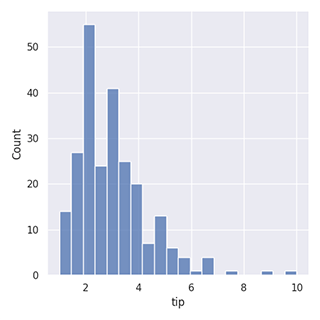
Histogramme avec la librairie Pandas (20 intervalles)
df['column1'].plot(kind='hist', bins=20)
Histogramme avec la librairie Seaborn (20 intervalles)
sns.displot(data=df, x='column1', bins=20)
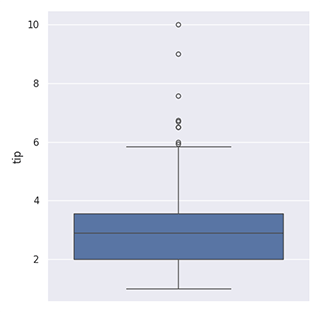
Boite à moustaches (Boxplot) avec la librairie Pandas
df['column1'].plot(kind='box')
Boite à moustaches (Boxplot) avec la librairie Seaborn
sns.catplot(data=df, y='column1', kind='box')
4. Analyse Multivariée
Entre deux variables discrètes
Table de contingence (table de dénombrement)
pd.crosstab(df['columnA'], df['columnB'])
Table de contingence normalisée
pd.crosstab(df['columnA'], df['columnB'], normalize=True)
Heatmap
sns.heatmap(pd.crosstab(df['columnA'], df['columnB']), annot=True)
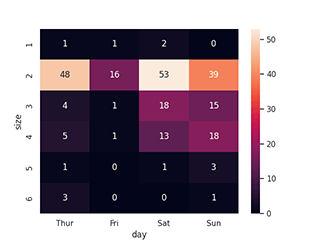
Entre une variable discrète et une variable continue
df.groupby('columnA')['column1'].describe()
df.groupby('columnA')['column1'].mean()
df.groupby('columnA')['column1'].median()
Histogramme x=column1 et y=column2
df.groupby('columnA')['column1'].mean().plot(kind='bar')
sns.catplot(data=df, x='columnA', y='column1', kind='bar')
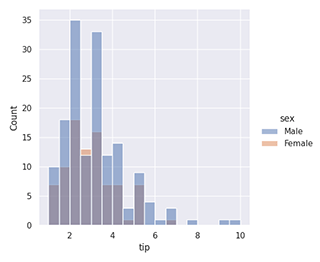
sns.displot(data=df, x='column1', hue='columnA')
Boxplots par columnA
sns.catplot(data=df, x='column1', hue='columnA', kind='box')
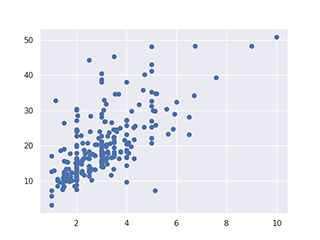
4.3 Entre deux variables continues
Nuage de points (scatter plot)
plt.scatter(df['column1'], df['column2'])
sns.scatterplot(data=df, x='column1', y='column2')